Learning speech representations by combining CL and MLM
Paper reading notes from w2v-BERT by Google Brain
- Objective: self-supervised speech representation learning by combining contrastive learning and masked language modeling.
- The idea of w2v-BERT is to use the contrastive task defined in wav2vec 2.0 to obtain an inventory of a finite set of discriminative, discretized speech units, and then use them as target in a masked prediction task in a way that is similar to masked language modeling (MLM) proposed in BERT for learning contextualized speech representations.
- We propose w2v-BERT that directly optimizes a contrastive loss and a masked prediction loss simultaneously for end-to-end self-supervised speech representation learning
- LibriSpeech task, real-world recognition task (voice search)
- analysis showing how CL and MLM are important and complement each other
- w2v-BERT = feature encoder + contrastive module + MLM module
- Uses conformers
- conformer layers, which combine convolution neural networks (CNNs) and transformers to model both local and global dependencies of audio sequences, are likely a better option for modeling speech than transformer layers and CNNs.
- Feature encoder = 2 2D conv layers with stride (2, 2) that result in a 4x reduction of input (mel spectrogram)
- Contrastive module = Linear projection layer + conformer (MHSA + depth-wise convolution + FFNN)
- output from feature encoder + masking $\rightarrow$ Contrastive module to get context vectors
- output from feature encoder $\rightarrow$ quantizer to get quantized vectors (like wav2vec 2.0) and assigned token IDs
- Contrastive loss between the two (like wav2vec 2.0)
- Masked prediction module = conformer blocks (same as in Contrastive module)
- Takes output from Contrastive module to give speech representations
- quantizer gives discretized speech tokens
- MLM loss between the two
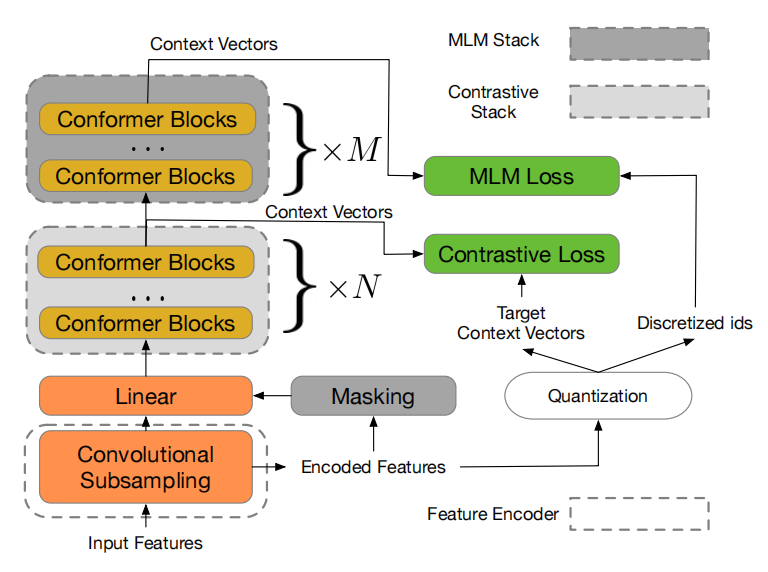
- Contrastive loss is used to train the Contrastive module along with the quantizer.
- Contrastive module will learn to give good context vectors for the Masked prediction module
- quantizer learns to produce discretized speech tokens used for MLM loss
- The masking after the Feature encoder is random (unlike wav2vec 2.0)
- For a context vector $c_t$ corresponding to a masked time step $t,$ the model is asked to identify its true quantized vector $q_t$ from a set of $K$ distractors ${\tilde q_1, \tilde q_2, \dots, \tilde q_K}$ that are also quantized vectors uniformly sampled from other masked time steps of the same utterance. (simple contrastive loss)
- We denote the loss as $\mathcal L_w,$ and further augment it with a codebook diversity loss $\mathcal L_d$ to encourage a uniform usage of codes. Therefore, the final contrastive loss is defined as: \(\mathcal L_c = \mathcal L_w + \alpha\cdot\mathcal L_d,\) where $\alpha=0.1.$
Q: what is codebook diversity loss, what is a codebook, what is codebook collapse?
- Simple cross-entropy loss for the masked prediction task $\mathcal L_m$
- w2v-BERT is trained two solve both at the same time \(\mathcal L_p=\beta\cdot\mathcal L_c+\gamma\cdot\mathcal L_m,\) and $\beta=\gamma=1$ in experiments.
- Pretraining is done with unlabeled speech data, fine-tuning with labeled data
- The contrastive module prevents code collapse, is what figure two shows
- watch the MlOps and OleWave videos
w2v-BERT is a model inspired by architectures like HUBERT, vq-wav2vec, DiscreteBERT and wav2vec2.0 that take in speech signals as input and learn speech representations. While HUBERT, vq-wav2vec, and DiscreteBERT produce discretized units for the Masked Language Modelling task, w2v-BERT improves on them by providing a way to learn them in an end-to-end manner. Finally, w2v-BERT builds on wav2vec2.0 by combining masked prediction with contrastive learning as opposed to the latter that only uses contrastive learning. The paper shows how contrastive learning overcomes common pitfalls like codebook collapse encountered by HUBERT. It beats a pure conformer model like wav2vec2.0 on voice search and demonstrates the need to combine contrastive learning with masked language modeling.
Following the loss functions will best help us understand the model. Briefly, contrastive learning is used to pick the correct quantized vector among quantized vectors from other time-stamps. This helps the quantizer learn better discretizations for the masked prediction task. Finally, a simple cross-entropy loss at the masked prediction module learns speech representations. The contrastive loss is augmented with codebook diversity loss which prevents codebook collapse as is demonstrated in Fig. 2 of the paper. The bulk of the learning is on the conformer blocks. This lets us conclude that there are three major ways we can understand/extend/generalize this method.
- Formulating the contrastive loss
- Different configuration of conformer blocks
- Better overall loss formulation (the paper just adds the losses together or uses numbers from the wav2vec paper)
In my opinion, the end to end learning that the model allows is one of it’s biggest strengths and that will let us experiment with different loss configurations or slight changes to model architectures.
The paper implements random masking which means that the burden is now on the training criterion to see what input samples can be used to learn meaningful representations. I believe this will improve the performance of these models. Something like the NeurIPS 2020 paper titled, “Not all unlabeled data are equal.”
A generalization that is of personal interest to me (based on my research) is to multi-modal input, specifically audio-visual data. Using different sets of input modalities and incorporating masking on each modality individually, we can extend the contrastive learning setup to multiple modalities. Although this might overextend the learning capabilities because this model already optimizes two loss functions.