Some known problems in text to image generation
Learning about where diffusion models break and collecting attempts at solutions
Text to image models run into a few common issues which I want to understand and investigate. They are as follows. Attribute binding: generated objects should faithfully adhere to prompts. Example: A black cube and a red sphere should not only generate the cube and sphere, but also correctly assign them their respective colours. Other similar issues are catastrophic neglect (where objects in prompt are not even generated), layout guidance (objects are not spatially placed according to the prompt), and colour leakage (one object presents with the attribute of another object)
Wiener Process
A Wiener process $W_t$ has the following properties:
- $W_0=0$
- $W_{t+u}-W_t, u\ge0$ are independent of past values $W_s,s\lt t$
- $W_{t+u}-W_t$ is normally distributed with mean $0$ and variance $u$
- $W_t$ is almost surely continuous in $t$
Reward Based Noise Optimization
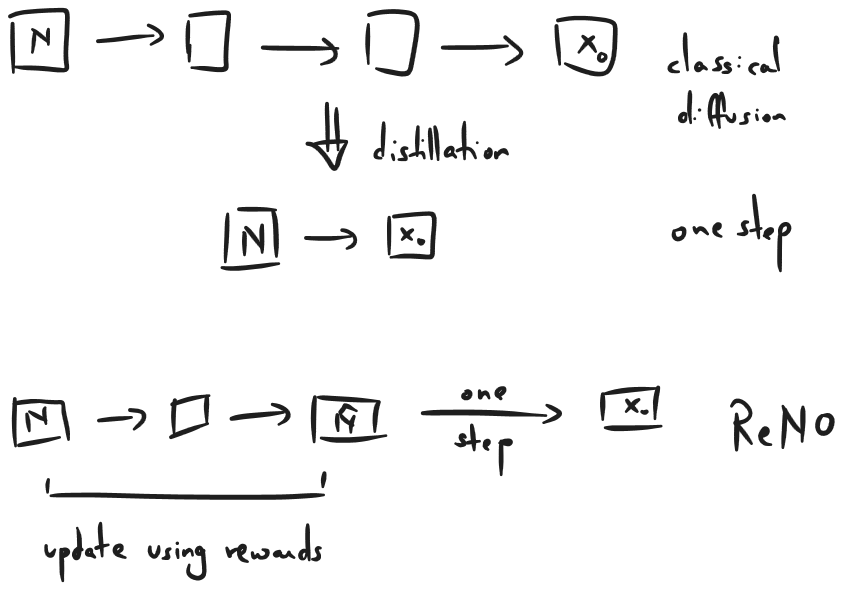
ReNO: difference between reward based noise optimization as proposed in ReNO (Eyring et al, NeurIPS 2024) and classical diffusion.
Questions and Todo
- Is ReNO different from just choosing the 50th/nth time step from the classical diffusion process and then using the one-step distillation?
- Why would GPU VRAM increase? Aren’t we just storing an image and a prompt for each run?
- How is Direct Preference Optimization different from Contrastive Learning?
- How are Denoising Diffusion Implicit Models different from DDPMs?
References
- ReNO
- Training Diffusion Models with Reinforcement Learning
- Diffusion Models Beat GANs on Image Synthesis